Agent Harness 工程(01):我们到底在给模型造什么?
Agent Harness 工程:给模型造一个能行动的世界
过去一年,“Agent”这个词被用得有点泛滥。
有些产品把几个 prompt 串起来,叫 Agent。 有些平台把一个拖拽式工作流包装一下,也叫 Agent。 还有些教程里,一个 while 循环加几个 tool calling,就已经开始讲“多智能体协作”了。
这不是说这些东西完全没价值。它们当然有价值,尤其在自动化流程、客服、数据查询、内容生成这些场景里。但如果我们认真讨论 Agent,就得先把一个问题说清楚:
真正产生 agency 的,不是外面那层编排代码,而是模型本身。
外部代码可以提供工具、环境、记忆、权限和反馈,但它不能凭空制造智能。模型能不能理解目标、能不能拆解任务、能不能根据反馈调整行动,这些能力主要来自训练。我们写的代码,更像是在给这个模型搭一个工作间。
这个工作间,就是 Harness。
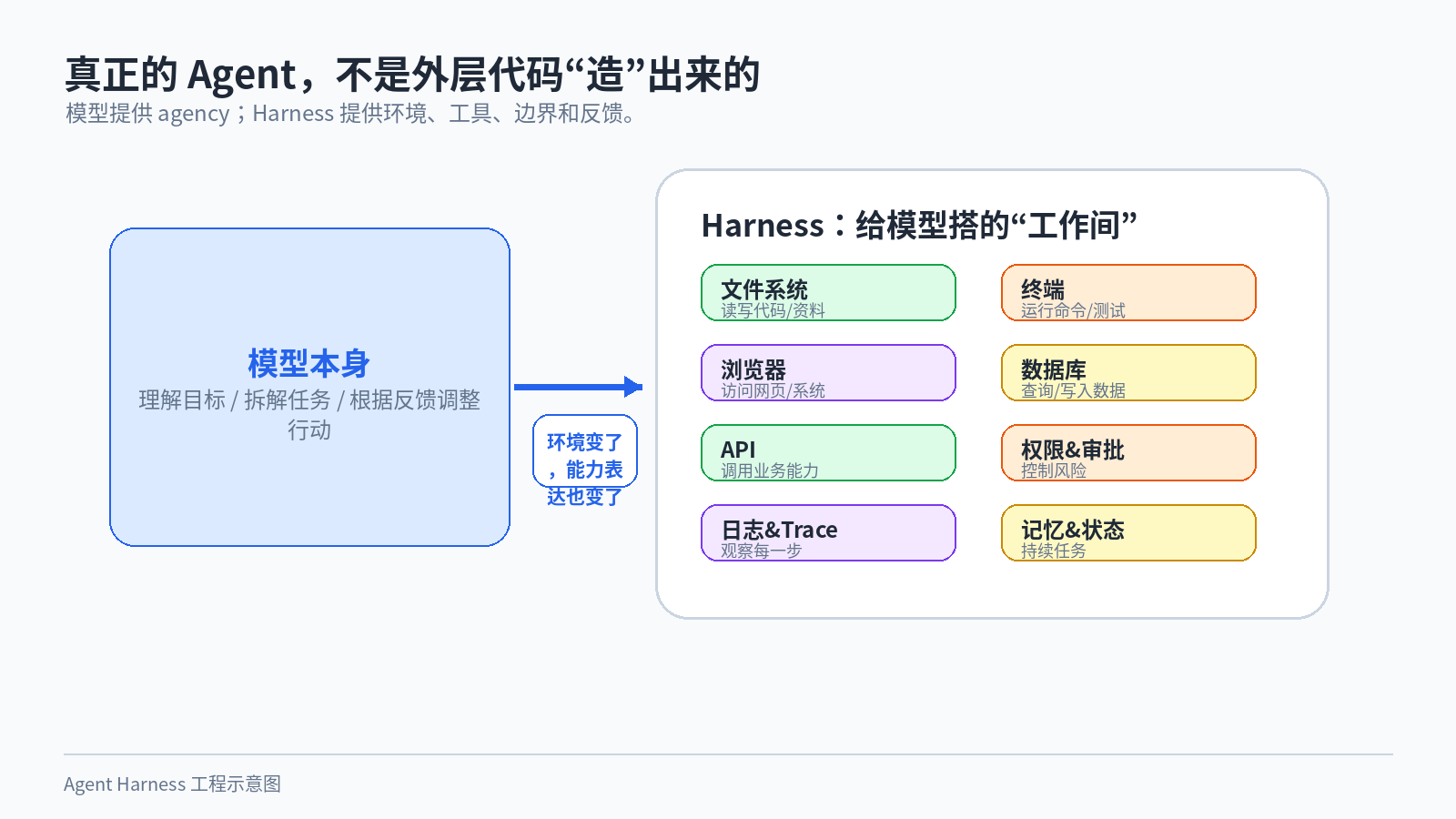
图 1:真正产生 agency 的是模型;Harness 更像模型的“工作间”。
不是“开发 Agent”,而是开发 Agent 的工作环境
很多人说自己在“开发 Agent”。但大多数时候,我们其实没有在开发 Agent 本身。
如果严格一点讲,开发 Agent 本身意味着你在训练模型,或者至少在通过微调、强化学习、偏好优化等方式改变模型的行为能力。DeepMind 训练 Atari Agent,OpenAI 训练 Dota Agent,Anthropic 和 OpenAI 训练会写代码、会用工具的大模型,这些才是在更本质意义上开发 Agent。
而普通工程师做的事情,大多是另一类工作:给模型提供一个可以行动的环境。
这个环境里有文件系统、终端、浏览器、数据库、API、文档、权限系统、日志系统和人工审批流程。模型负责判断下一步要做什么,Harness 负责让它真的能做,并且尽量别把事情做坏。
拿编程 Agent 举例。模型本身并不“拥有”代码库。它需要 Harness 帮它读取文件、搜索符号、查看 git diff、运行测试、修改代码、提交 patch。Claude Code、Codex 这类产品真正做得好的地方,不只是模型会写代码,而是它们把代码库、终端、测试、版本控制和权限边界组织成了一个适合模型工作的环境。
这也是为什么一个强模型放在普通聊天框里,和放在一个好的 coding harness 里,表现会差很多。
前者只能“建议你怎么改”。 后者可以自己读、自己改、自己跑测试,然后根据错误继续修。
模型没有变,环境变了,能力的表达方式就变了。
最小 Agent Loop 仍然重要,但它只是起点
最小的 Agent Harness 其实很简单。
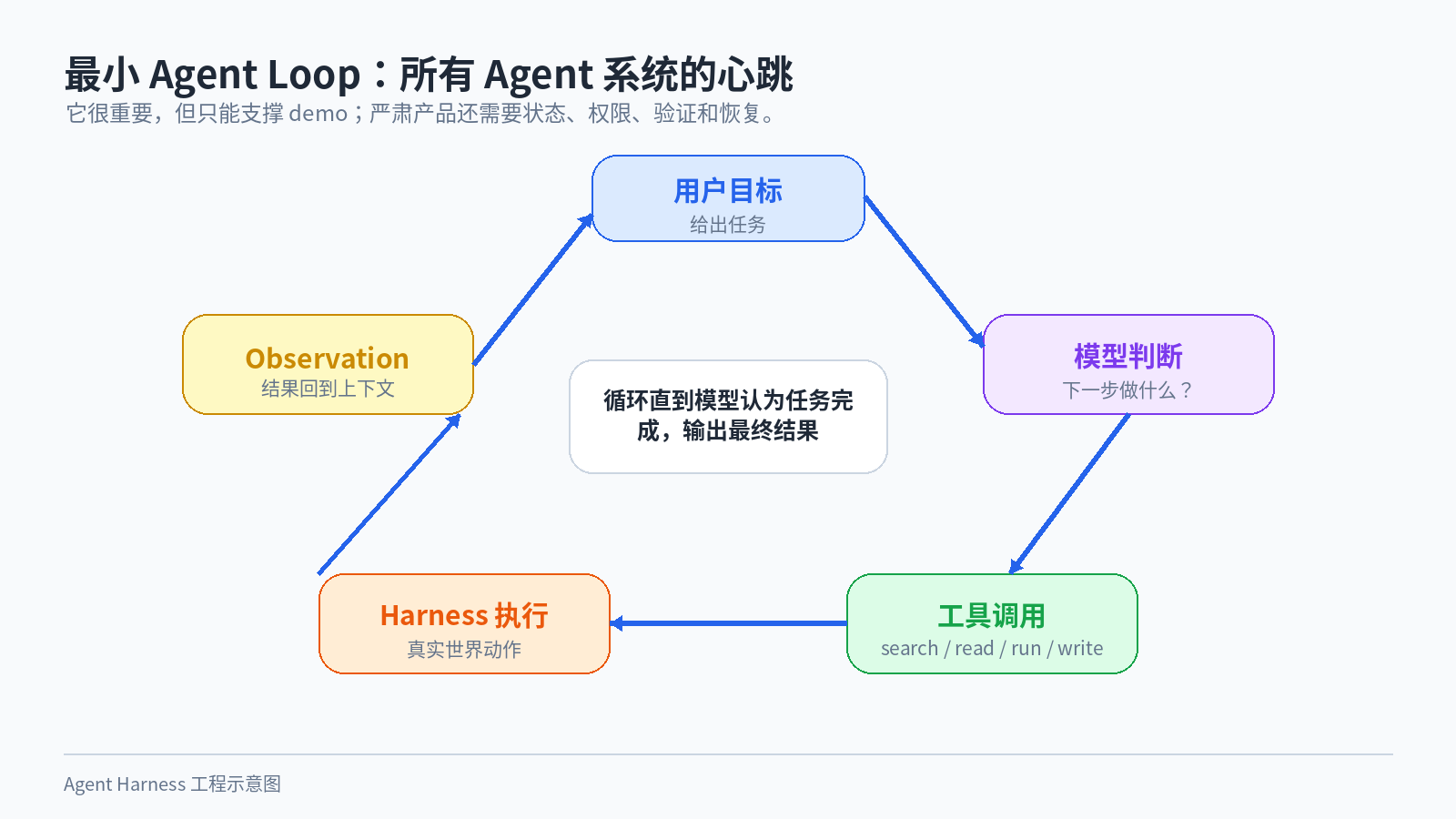
图 2:用户目标、模型判断、工具调用、Harness 执行和 observation 构成最小循环。
用户给一个目标,模型思考下一步。如果模型要调用工具,Harness 执行工具,把结果塞回上下文,模型继续判断。直到模型认为任务完成,输出最终结果。
这个循环很基础,但它仍然是所有 Agent 系统的心跳。
问题在于,只靠这个循环做不了严肃产品。
因为真实场景里会遇到很多麻烦:工具调用失败怎么办?模型误删文件怎么办?上下文越来越长怎么办?任务做到一半中断了,明天还能不能恢复?模型说自己完成了,怎么证明真的完成了?某一步操作会影响生产环境,要不要让人确认?
这些问题都不是多写几句 prompt 能解决的。
prompt 可以影响模型的行为倾向,但它不能替你提供权限隔离,不能替你做状态持久化,也不能替你保证测试一定跑过。真正复杂的部分,最后都会落回工程系统。
所以,Agent Harness 的第一层是 tool loop;第二层才是真正麻烦的东西:状态、上下文、权限、验证和恢复。
Harness 正在变成 Runtime
早期大家做 Agent,很容易写成一个脚本:
模型输出 tool call,代码执行,再把 observation 追加回去。这个东西能跑 demo,但离生产系统还差很远。
现在更前沿的做法,是把 Harness 做成一个 Agent Runtime。
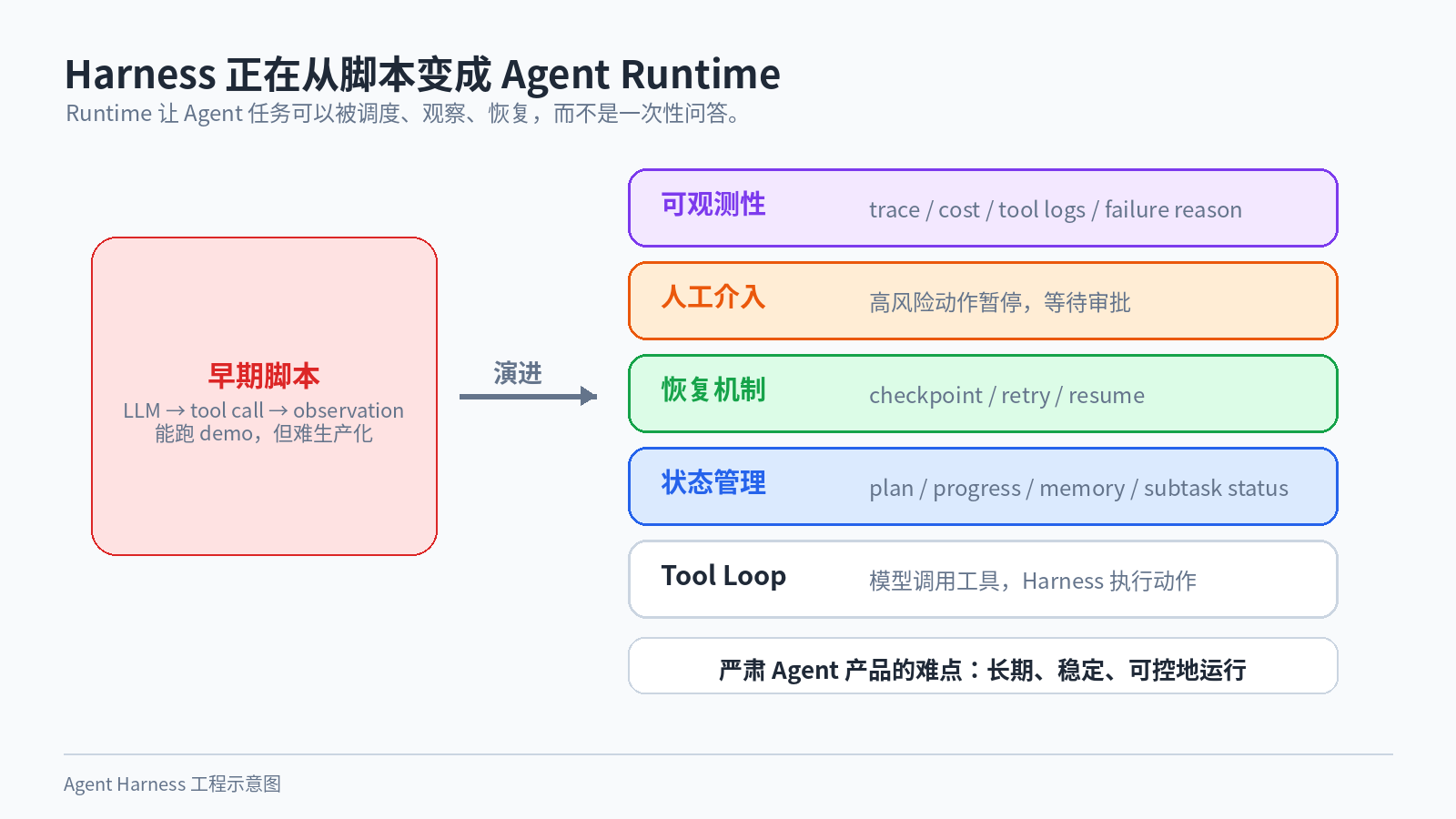
图 3:Runtime 关注的是任务能不能被调度、观察、恢复和控制。
Runtime 这个词很关键。它意味着 Agent 不是一次性的问答,而是一个可以被调度、被观察、被恢复的运行中任务。
一个像样的 Agent Runtime,至少要处理几件事。
首先是状态。Agent 做到哪一步了?已经读过哪些文件?当前计划是什么?哪些子任务完成了?哪些失败了?这些东西不能只存在上下文里,否则一旦上下文被压缩、会话中断或者进程重启,任务就断了。
其次是恢复。一个长任务不可能永远一次跑完。中途可能等用户审批,可能工具超时,可能外部系统报错。Runtime 要能把任务 checkpoint 下来,之后继续执行。
然后是人工介入。越是能行动的 Agent,越不能完全放飞。低风险动作可以自动执行,高风险动作必须停下来等人确认。比如读文件可以自动,删数据库就不能自动。
最后是可观测性。Agent 为什么做了这个决定?调用了哪些工具?花了多少钱?哪一步失败了?失败是模型判断错了,还是工具返回错了?这些都要能追踪。
这也是为什么 LangGraph、OpenAI Agents SDK、Google ADK、Microsoft Agent Framework 这类东西都在强调 runtime、workflow、state、handoff、human-in-the-loop、trace,而不是只讲 prompt chain。
行业已经慢慢意识到:Agent 产品的难点不在于把 LLM API 调起来,而在于让这个东西长期、稳定、可控地运行。
MCP 的意义:工具不该永远手写
过去做 Agent,很大一部分工作是在手写工具。
今天接 GitHub,明天接 Slack,后天接数据库。每个工具都要定义参数、返回格式、鉴权方式、错误处理和权限边界。项目一复杂,工具层就会变成一堆胶水代码。
MCP 的价值就在这里。
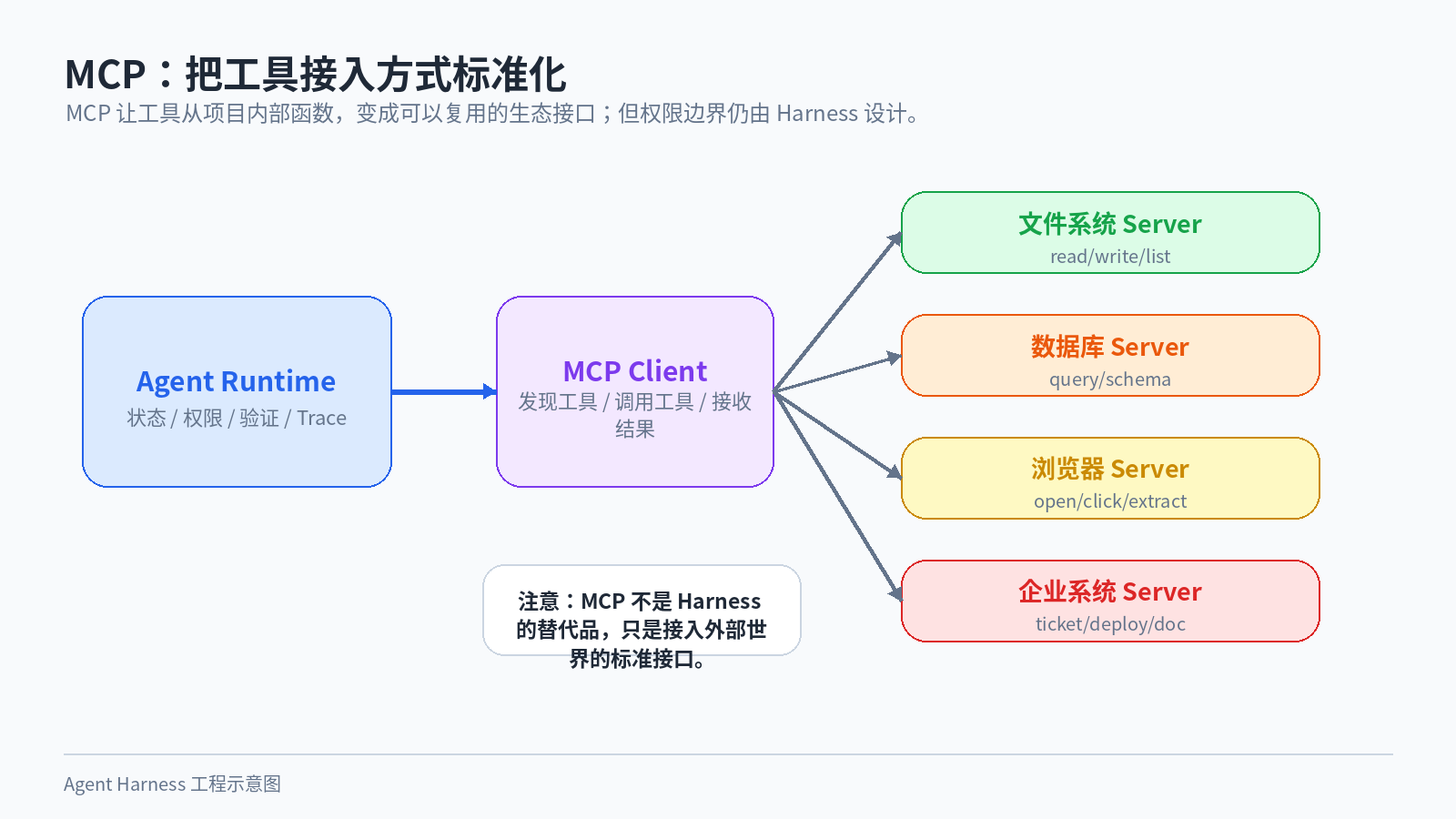
图 4:MCP 让外部工具变成可复用接口,但安全、权限和验证仍然属于 Harness 的核心职责。
它试图把 Agent 连接外部世界的方式标准化。外部系统可以暴露 MCP server,Agent 应用作为 client 去连接。这样一来,文件系统、数据库、浏览器、搜索、内部文档、企业系统,都可以用相对统一的方式接入模型。
这件事的意义不只是“少写点代码”。
更大的变化是:工具开始从项目内部的函数,变成一种生态接口。
以后一个 Agent Runtime 不一定需要内置所有工具。它可以通过 MCP 发现工具、调用工具、组合工具。企业内部也可以把自己的知识库、工单系统、部署平台、数据平台包装成 MCP server,供不同 Agent 使用。
但这也会带来新的问题。
工具越容易接,风险也越容易扩散。一个 Agent 如果能同时连文件系统、数据库、浏览器和企业 IM,那它的权限边界必须设计得非常清楚。哪些工具只读?哪些工具需要审批?哪些工具不能访问生产数据?工具返回的信息里有没有 secret?这些都不是 MCP 自动帮你解决的。
所以 MCP 不是 Harness 的替代品。 它更像是 Harness 接入外部世界的一种标准接口。
真正难的,还是怎么安全地用这些接口。
上下文工程比 RAG 更重要
很多人一说 Agent,就会想到 RAG。但在 Agent 系统里,RAG 只是上下文工程的一部分。
RAG 解决的是“从资料里找相关内容”。 Context Engineering 解决的是“在任务执行过程中,模型到底应该看到什么”。
这两个问题不是一回事。
一个长任务里,模型不可能一直带着全部信息行动。代码库太大,文档太多,历史步骤太长,工具返回也可能很啰嗦。如果所有东西都往上下文里塞,模型很快就会被噪声淹没。
更好的方式是按需加载。
模型不需要一开始读完整个 repo。它可以先搜索文件名和符号,找到相关模块,再读关键文件。它不需要记住每一条日志,只需要保留当前假设、失败原因和下一步计划。它也不需要把所有历史对话都带着,只需要在必要时读取任务状态或压缩摘要。
这就是 coding agent 里很常见的一种工作方式:
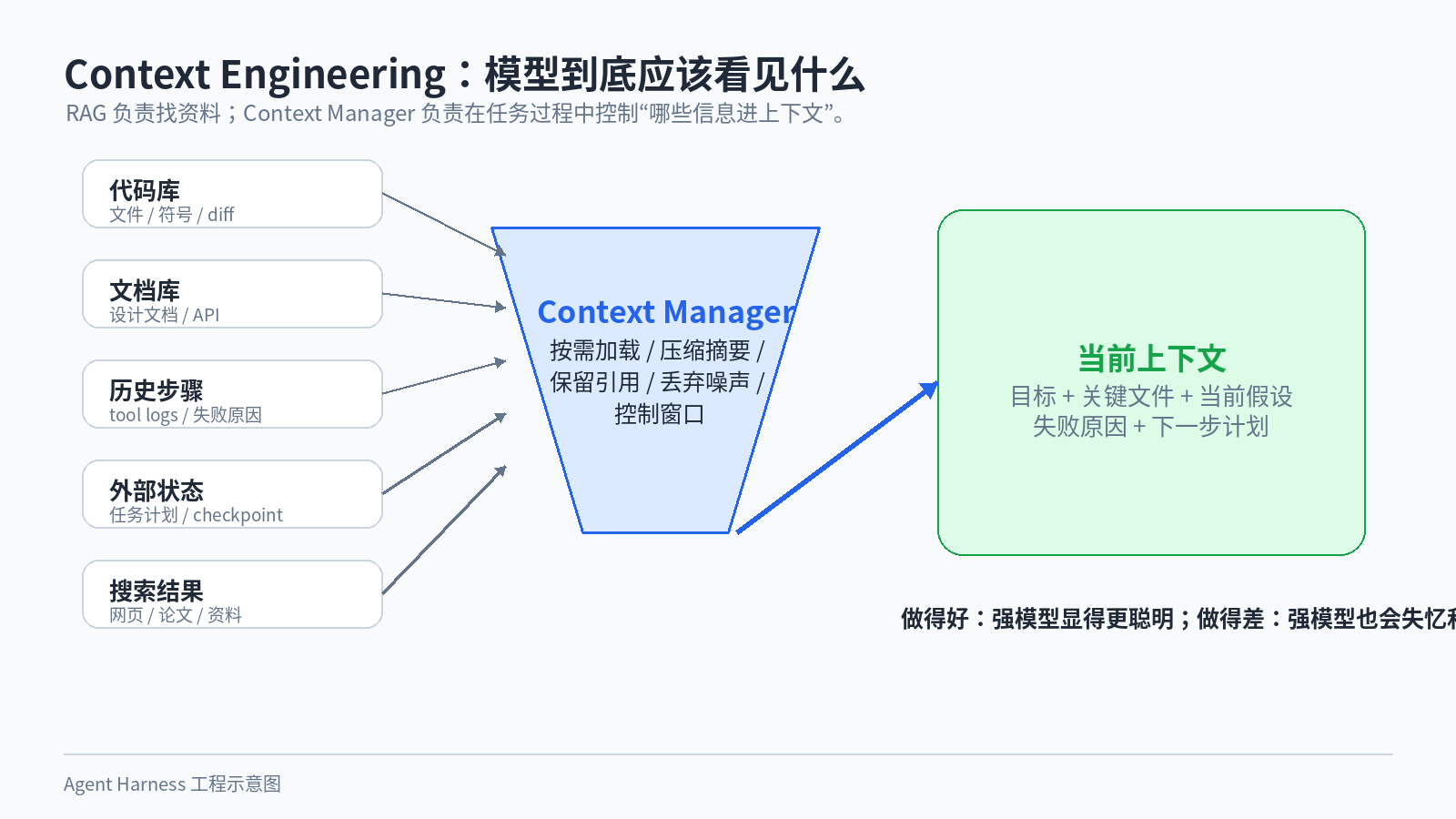
图 5:RAG 只是“找资料”,Context Engineering 更关心任务过程中信息如何进入上下文。
先 grep,再读文件; 先看接口,再看实现; 先小范围修改,再跑测试; 测试失败后,再根据错误回到相关代码。
这不是简单的“检索增强生成”。 它更像是模型在一个信息空间里主动导航。
所以 Harness 里应该有一个很重要的模块:Context Manager。
它要决定哪些信息进入当前上下文,哪些信息放到外部状态,哪些信息只保留引用,哪些信息应该被压缩,哪些信息应该丢弃。
这件事做得好,模型会显得很聪明。 做得差,强模型也会变得像失忆、啰嗦、抓不住重点。
Skills:把经验打包,而不是把 prompt 写长
还有一个很值得关注的趋势是 Skills。
过去我们经常用很长的 system prompt 告诉模型怎么做事。比如代码规范是什么,测试怎么跑,部署流程是什么,遇到错误怎么处理。问题是 prompt 一长,就很难维护,也很难复用。
Skills 提供了另一种思路:把某类任务需要的说明、脚本、模板和参考资料打包起来,让模型在需要的时候加载。
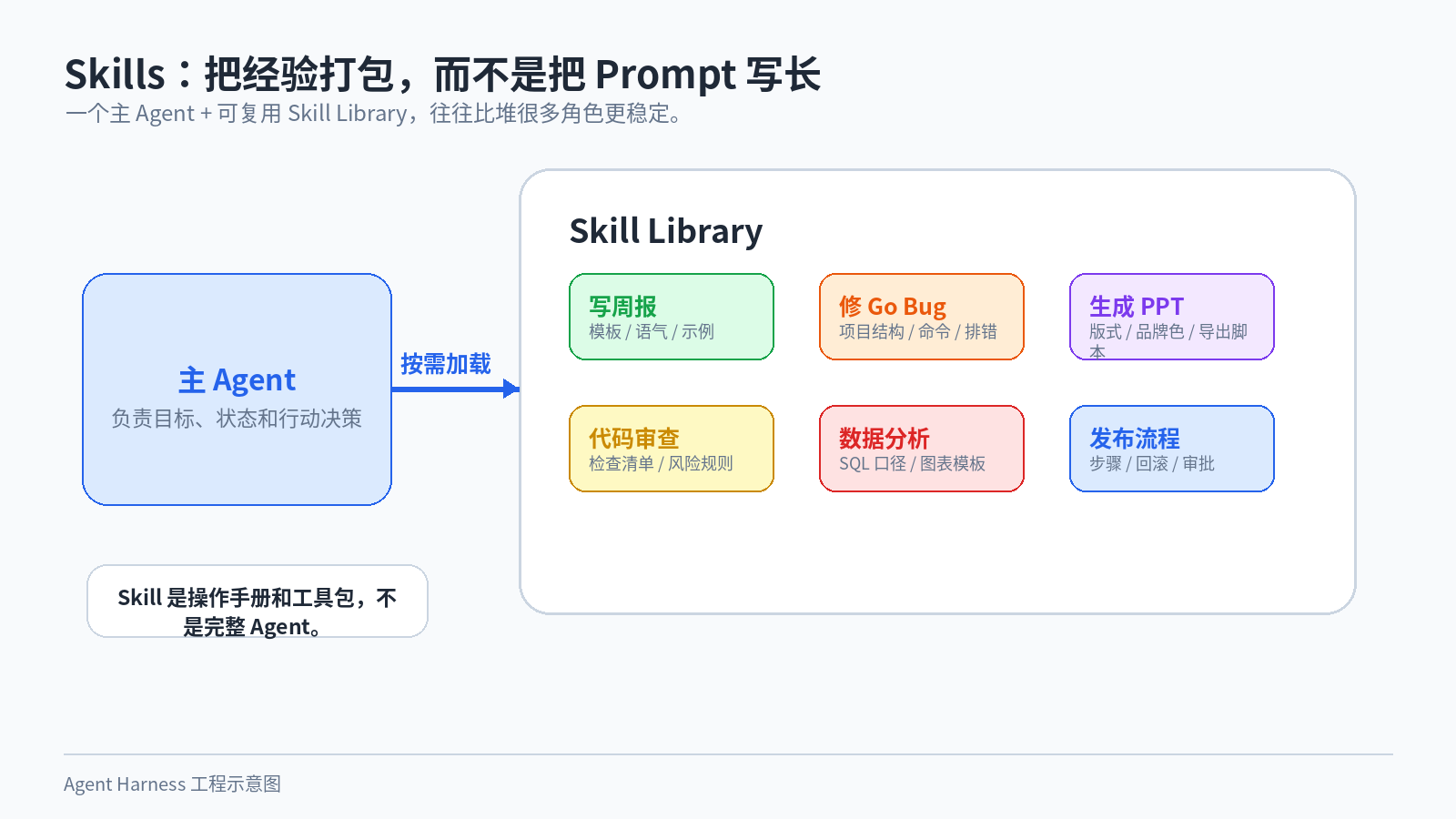
图 6:Skill 更像可复用的操作手册和工具包,而不是完整 Agent。
比如一个“写周报”的 skill,里面可以有公司周报模板、语气要求、示例和检查规则。一个“修复 Go 服务 bug”的 skill,里面可以有项目结构说明、常用命令、日志位置、测试方式和排错流程。一个“生成 PPT”的 skill,可以包含版式规范、品牌色、图表模板和导出脚本。
Skill 不是完整 Agent。 它更像是给 Agent 用的操作手册和工具包。
这比“为每个任务造一个 Agent”更可控。
很多 multi-agent 系统之所以不稳定,就是因为里面塞了太多角色。Planner、Researcher、Writer、Reviewer、Critic 一起聊天,表面上很热闹,实际上经常是在互相消耗上下文。
如果一个强模型本来就能处理多种任务,那么很多时候没必要拆成一堆 Agent。更合理的做法是:保留一个主 Agent,然后给它一套高质量的 skill library。模型根据任务需要加载对应 skill。
未来企业内部真正有价值的,可能不是“我们做了多少 Agent”,而是“我们沉淀了多少可复用的 Skills”。
因为 Skills 才是组织经验的载体。
Multi-Agent 不是群聊,而是隔离和并行
当然,这不是说 Multi-Agent 没用。
Multi-Agent 有用,但它不应该被理解成“几个 AI 角色坐在一起开会”。
真正有价值的 Multi-Agent,通常是为了解决三个问题:隔离上下文、并行执行、专业验证。
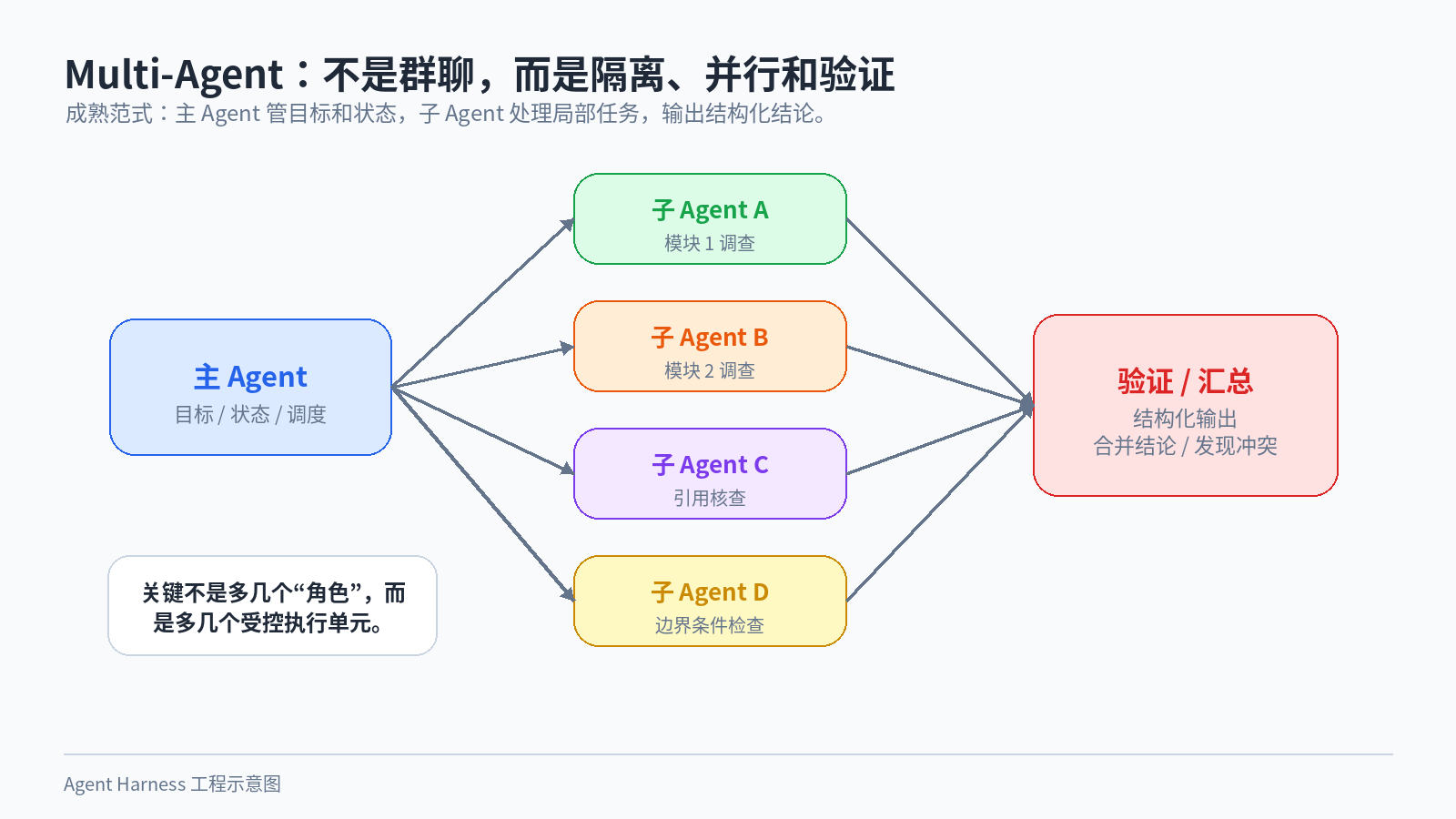
图 7:Multi-Agent 的重点不是角色扮演,而是隔离、并行和可验证的结构化输出。
比如一个复杂代码任务,主 Agent 可以负责总体计划,让几个子 Agent 分别调查不同模块。每个子 Agent 只看自己相关的文件,最后返回结构化结论。这样既节省主上下文,也能并行探索。
再比如一个研究任务,可以让一个 Agent 找论文,一个 Agent 做引用核查,一个 Agent 写初稿,一个 Agent 专门检查 claim 和 citation 是否匹配。但这里的关键不是“角色扮演”,而是每个 Agent 有明确输入、明确输出和明确的验证标准。
不受控的 Multi-Agent 很容易变成 token 黑洞。
几个 Agent 互相评论、互相赞同、互相补充,最后产出一堆看似合理但没人验证的文本。这样的系统不但贵,而且不可靠。
所以更成熟的范式是:主 Agent 负责状态和目标,子 Agent 负责局部任务。子 Agent 的上下文要隔离,输出要结构化,关键结果要验证。能并行就并行,不能并行就不要强行“多智能体”。
Multi-Agent 的本质不是多几张嘴,而是多几个受控的执行单元。
Verification:Agent 不能只靠“看起来对”
Agent 系统最大的问题,不是它不会做事,而是它做错了还很自信。
这在写代码时尤其明显。模型可以生成一段看起来很合理的实现,但测试没跑,边界条件没处理,类型也可能不对。如果 Harness 只是把结果展示给用户,那这个 Agent 其实只完成了一半。
一个好的 Harness 必须有验证层。
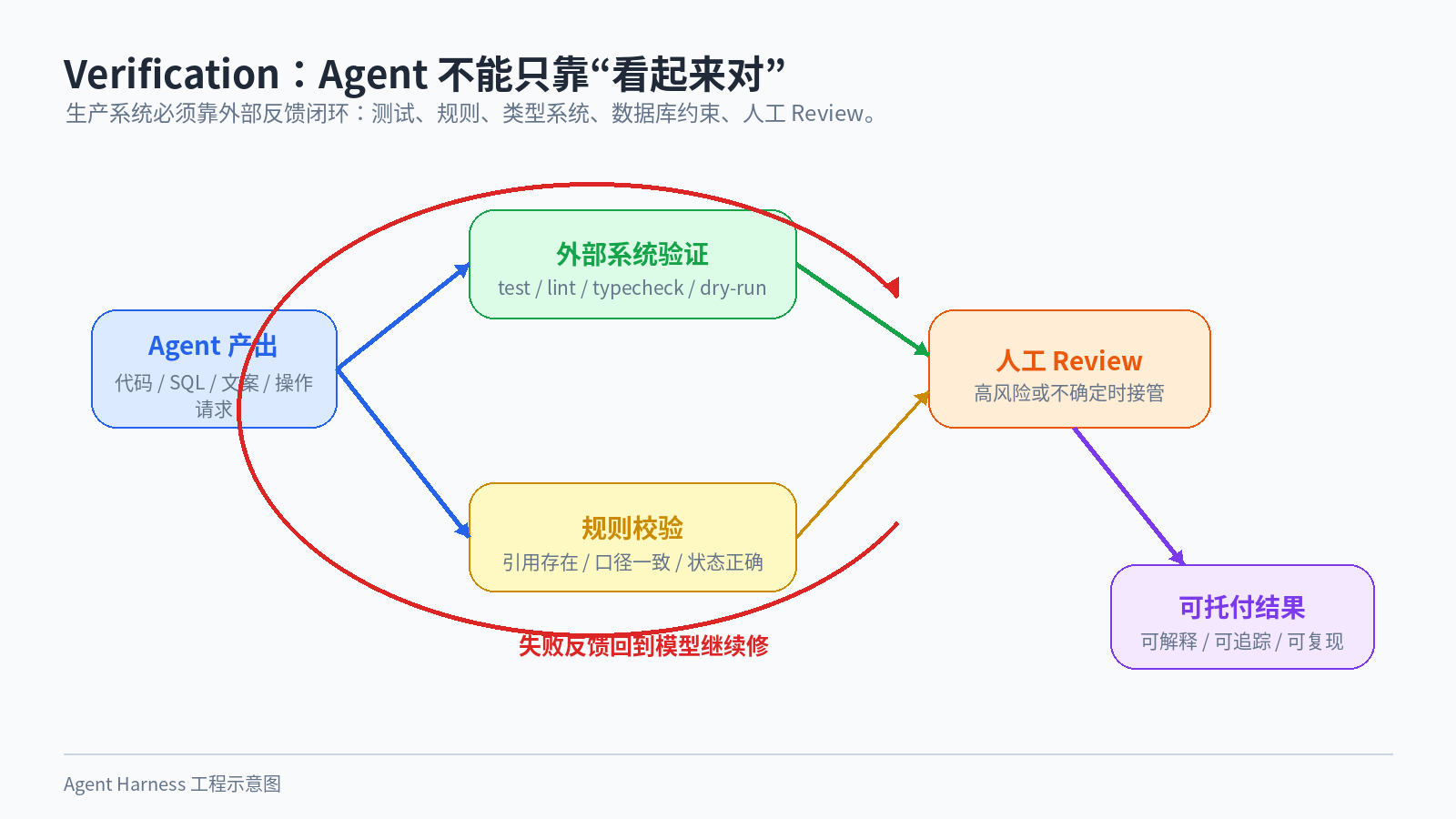
图 8:Agent 结果不能只看“像不像对”,要用外部系统反馈来闭环验证。
在 coding agent 里,验证很自然:跑测试、跑 lint、跑 type check、看 build 是否通过。结果好不好,不只看模型怎么说,而是看外部系统怎么反馈。
在研究 Agent 里,验证可能是引用是否存在、论文是否真的支持这个 claim、是否有多个来源交叉确认。
在数据分析 Agent 里,验证可能是 SQL 是否 dry run 通过、行数是否异常、指标口径是否和文档一致。
在业务流程 Agent 里,验证可能是订单状态是否真的更新、邮件是否真的发出、审批是否完成、外部系统返回是否成功。
验证层不一定非得是另一个 LLM。很多时候,测试、规则、类型系统、数据库约束和人工 review 比 LLM judge 更可靠。
这点很重要。
Demo 可以靠模型输出。 生产系统必须靠外部反馈。
没有验证闭环的 Agent,很难真正托付任务。
权限层是 Harness 的核心,不是附属功能
Agent 一旦能行动,就一定会涉及权限。
能读文件,就可能读到敏感文件。 能写文件,就可能改坏代码。 能跑 shell,就可能执行危险命令。 能操作浏览器,就可能点错按钮。 能连数据库,就可能查到或改到不该碰的数据。
所以权限层不是产品上线前补一个安全弹窗,而是 Harness 一开始就要设计的核心部分。
好的权限设计应该分层。

图 9:读、写、提交、删除等动作风险不同,应该对应不同的自动化和审批策略。
只读操作可以相对放宽。 可回滚操作可以自动执行,但要留日志。 不可逆操作必须审批。 高风险系统默认不开放,或者只开放沙箱环境。
比如 coding agent 里,读代码、搜索文件一般问题不大;修改文件需要让用户看 diff;提交 PR 可以让 Agent 做,但 merge 进主分支最好仍由人确认;删除文件、改 CI、动部署脚本这些操作就应该更谨慎。
在企业系统里也是一样。Agent 可以帮你查订单、生成回复、准备审批材料。但真正退款、发合同、改生产配置、删除数据,通常都应该有人类确认。
成熟的 Agent 产品不会追求“全自动”。 它追求的是把不同风险级别的动作放到合适的控制层里。
这也是 Harness 工程和安全工程交叉最深的地方。
Coding Agent 为什么是最好的观察样本
如果想理解 Agent Harness,最值得研究的不是那些看起来花哨的“通用智能体平台”,而是 coding agent。
原因很简单:软件工程天然适合 Agent。
它有清楚的环境:代码库、文件、终端、Git。 它有清楚的动作:读、写、搜索、运行命令。 它有清楚的反馈:编译错误、测试失败、lint 报错。 它有清楚的产物:diff、commit、PR。 它也有天然的人工审核机制:code review。
这让 coding agent 形成了一个很完整的闭环。
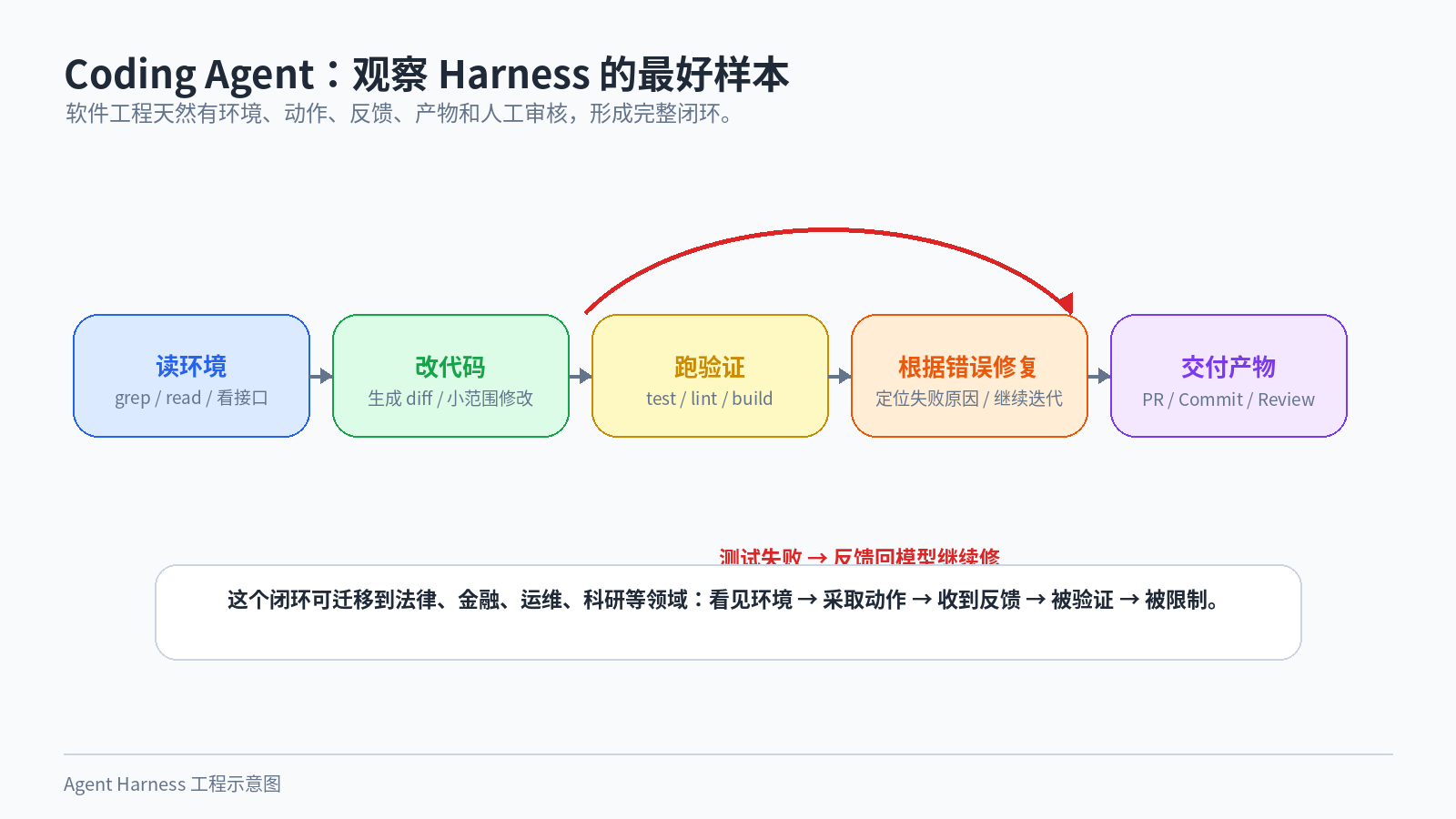
图 10:代码库、终端、测试、diff 和 code review 让 Coding Agent 成为研究 Harness 的最佳样本。
模型读代码,提出修改,Harness 执行修改,测试系统给反馈,模型根据反馈继续修,最后产出 diff 给人类 review。
这个闭环非常适合迁移到其他领域。
法律 Agent 也需要资料、引用、审查和人工确认。 金融 Agent 也需要数据、规则、风控和审计。 运维 Agent 也需要监控、命令、回滚和审批。 科研 Agent 也需要文献、实验、复现和同行检查。
领域不同,工具不同,但 Harness 的骨架很像:让模型能看见环境,能采取动作,能收到反馈,能被验证,也能被限制。
真正的 Agent 产品不是“更自主”,而是“更可托付”
很多人谈 Agent 前沿时,容易把方向理解成“让 AI 更自主”。这只说对了一半。
用户真正需要的不是一个完全自主、谁也管不住的系统。用户需要的是一个可以托付任务的系统。
可托付意味着什么?
它知道自己在做什么。 做错了能被发现。 卡住了会说明原因。 危险动作会停下来问人。 中断后可以恢复。 每一步都有记录。 最终结果可以验证。
这和“自主”不是一回事。
一个系统可以非常自主,但完全不可靠。 也可以在关键节点受控,却非常好用。
所以未来 Agent 产品的成熟度,不应该只看它能不能连续执行 100 步,而应该看它执行这 100 步时,有没有状态管理、权限控制、验证机制和错误恢复。
Agent 的前沿,不是把人类从流程里彻底拿掉。 更现实的方向是:让机器承担低风险、高重复、多步骤的部分,让人类保留目标设定、关键判断和最终责任。
这可能没有“全自动 Agent”听起来酷,但更接近真实落地。
结语:Harness 工程师是在给模型造世界
如果把模型比作一个会思考的驾驶者,那么 Harness 就是道路、仪表盘、方向盘、刹车、导航、交通规则和安全气囊。
没有驾驶者,车不会自己去哪。 没有车,驾驶者也只能停留在原地。
所以我们做 Agent Harness,并不是在“写智能”。我们是在把智能接入世界。
这个世界要让模型看得见信息,调得动工具,记得住状态,理解得了反馈,也碰不到不该碰的东西。它要允许模型试错,但不能让试错变成事故。它要让模型有发挥空间,也要让人类能随时理解和接管。
这就是 Agent Harness 工程真正有意思的地方。
它不像训练大模型那样遥远,也不像写 prompt 那样轻飘。它是一个很工程、很现实、也很有想象力的方向。
未来几年,很多所谓 Agent 产品会被证明只是包装过的工作流。但也会有一些真正好用的 Agent 出现。它们未必最会喊口号,未必界面最酷,甚至未必自称“完全自主”。
但它们会有一个共同点:
背后都有一个扎实的 Harness。
