从 Dubbo 到 Dubbo-Go:Metadata 到底解决了什么问题?
从应用级服务发现、revision、mapping 到元数据治理体系的源码对比
很多人第一次看到 Dubbo 的 metadata,会把它理解成一组“服务描述信息”:
这个服务叫什么?
有哪些方法?
group 是什么?
version 是什么?
protocol 是什么?这些当然是 metadata 的一部分,但如果只停留在这个层面,就会低估它在 Dubbo 3 应用级服务发现中的位置。
在 Dubbo 3 之后,metadata 不再只是“补充说明”,而是应用级服务发现能够真正落地的关键模块。
一句话概括:
注册中心负责告诉 consumer:有哪些应用实例在线;metadata 负责告诉 consumer:这些实例到底提供了哪些 Dubbo 服务。
本文会从应用级服务发现的背景切入,对比 Dubbo Java 当前 metadata 体系 与 Dubbo-Go 3.0 metadata 设计,重点看它们在职责边界、数据模型、存储交互、性能优化和工程成熟度上的差异。
1. 为什么 Dubbo 3 需要 metadata?
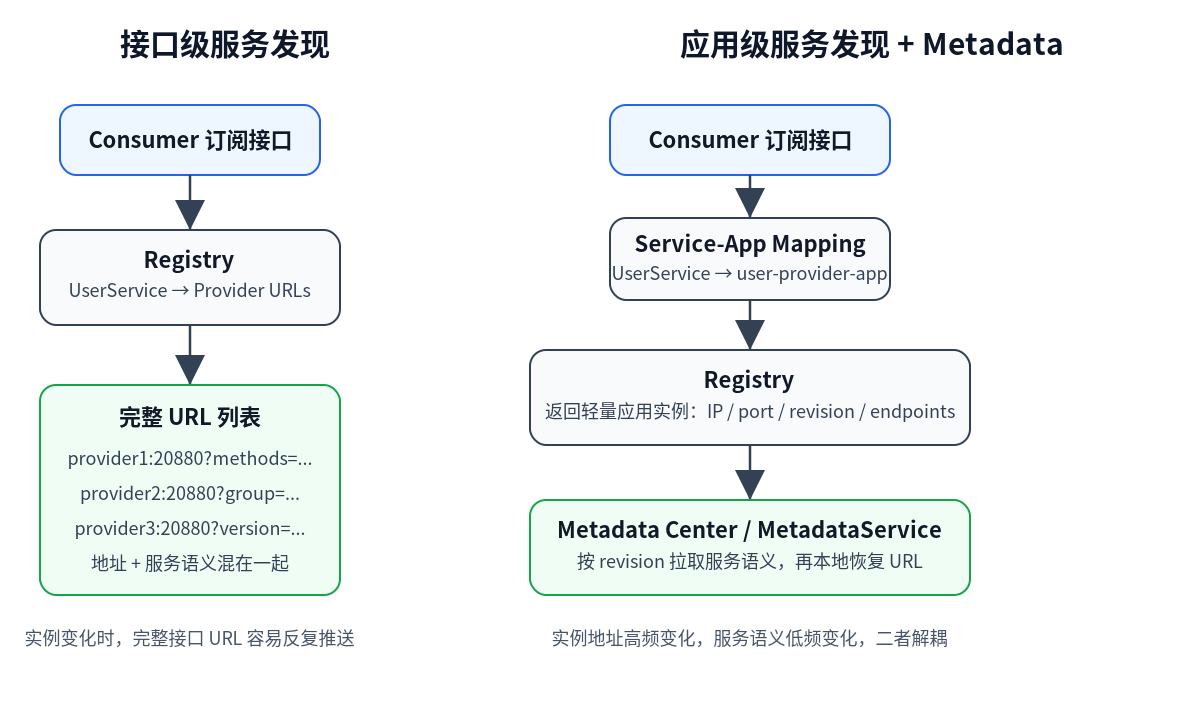
在传统的接口级服务发现里,consumer 订阅的是接口。
比如 consumer 要调用:
org.example.UserService注册中心直接返回:
UserService -> provider1:20880
UserService -> provider2:20880
UserService -> provider3:20880这个模型非常直观,因为注册中心里存的就是“接口到地址”的关系。
但 Dubbo 3 更强调应用级服务发现。注册中心里更核心的对象不再是某个接口,而是某个应用实例。例如:
user-provider-app
-> 10.0.0.1:20880
-> 10.0.0.2:20880
-> 10.0.0.3:20880问题也随之出现:consumer 拿到的是应用实例,但真正要调用的是接口。
那么 consumer 怎么知道:
user-provider-app 到底暴露了哪些接口?
这些接口的 group、version、protocol 是什么?
methods 有哪些?
某个接口到底由哪些应用提供?这些问题不适合全部交给注册中心回答。注册中心更擅长维护“谁在线、地址是什么、实例是否变化”;而接口、方法、协议参数、服务语义这些信息如果全部塞进注册中心,会让注册数据迅速膨胀。
因此,metadata 在 Dubbo 3 中承担了一个更清晰的角色:
注册中心负责发现实例,metadata 负责解释实例。
2. 用一个类比理解 metadata:地图和菜单
可以把应用级服务发现想象成外卖平台。
注册中心像地图,它告诉你:
附近有哪些餐厅开门?
餐厅地址在哪里?
餐厅是否在线?但光知道餐厅地址还不够。你还要知道:
这家餐厅卖什么菜?
菜单有没有变化?
某道菜由哪几家餐厅提供?
不同门店菜单是否一致?metadata 就像菜单。
在 Dubbo 里,这个类比可以对应成:
应用实例 = 餐厅门店
接口服务 = 菜品
metadata = 菜单
revision = 菜单版本号
service mapping = 菜品到餐厅的映射
metadata center = 菜单中心如果餐厅只是扩容了一个新门店,但菜单没变,那么 consumer 不需要重新读取完整菜单;如果菜单变了,只需要根据新的 revision 拉取一次新的 metadata。
这就是 metadata 的第一个核心价值:
把高频变化的实例地址和低频变化的服务语义拆开。
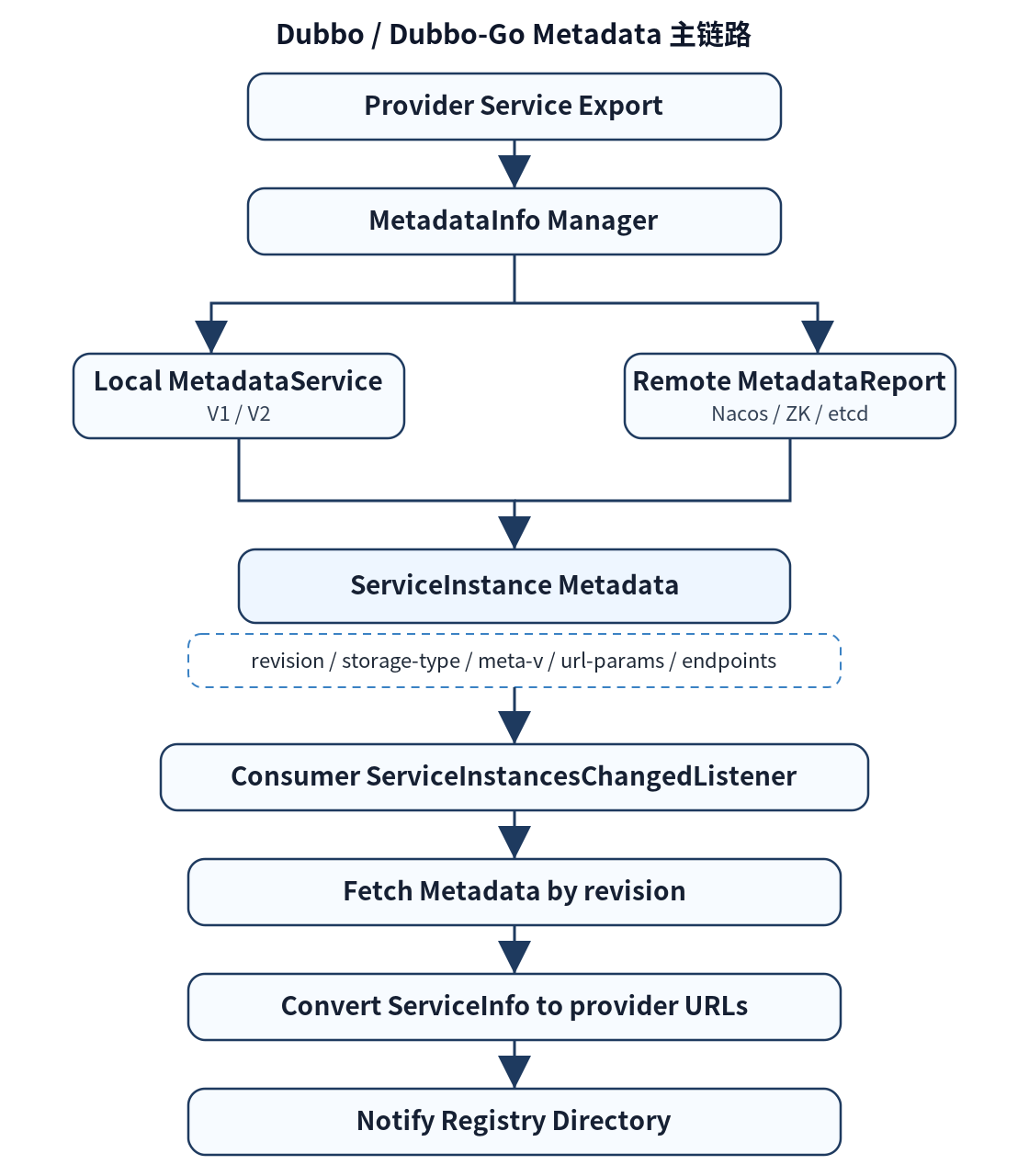
3. Dubbo-Go 3.0 metadata:核心目标是恢复服务视图
Dubbo-Go 3.0 的 metadata 设计主线相对清晰,它主要解决三个问题。
3.1 Provider 当前到底暴露了哪些服务?
一个 provider 应用启动后,可能同时暴露多个接口:
UserService OrderService PaymentService每个接口又可能带有自己的:
group version protocol path methods这些信息会组成一份应用级 metadata。
3.2 如何判断服务集合是否发生变化?
Dubbo-Go 会给这份服务集合生成 revision。
revision 可以理解成当前服务视图的摘要。如果 provider 暴露的服务集合没有变化,revision 就不变。consumer 看到 revision 没变,通常就不需要重新拉取完整 metadata。
3.3 如何从接口找到应用?
应用级服务发现中,注册中心认识的是应用;但 Dubbo consumer 很多时候还是从接口开始订阅。
所以系统必须维护:
org.example.UserService -> user-provider-app这就是 service-app mapping。
Dubbo-Go 3.0 中,consumer 的大致流程可以概括为:
从接口出发
-> 通过 mapping 找到应用名
-> 监听应用实例
-> 读取实例 revision
-> 根据 revision 获取 metadata
-> 把实例地址和 metadata 组合成最终服务 URL所以,Dubbo-Go 3.0 的 metadata 可以概括为:
应用级服务发现的最小完整语义层。
它不追求一开始就做成庞大的治理体系,而是优先保证应用级服务发现的主链路能够跑通。
4. Dubbo Java metadata:已经演进成完整元数据体系
Dubbo Java 当前源码中的 metadata 更复杂。它不只是保存“服务清单”,而是把服务发现、元数据中心、服务定义、接口应用映射、实例 metadata、远程 MetadataService、缓存、重试和治理能力都串了起来。
最核心的类是:
org.apache.dubbo.metadata.MetadataInfo在 Dubbo Java 中,MetadataInfo 不仅包含:
app
revision
services还包含:
rawMetadataInfo
subscribedServices
extendParams
instanceParams
subscribedServiceURLs
exportedServiceURLs其中 services 的 key 通常形如:
{group}/{interface name}:{version}:{protocol}这说明 Dubbo Java 的 MetadataInfo 不是简单的接口列表,而是一份运行时服务语义快照。
同时,MetadataInfo.ServiceInfo 里还保存了:
name
group
version
protocol
port
path
params
methodParams
consumerParams
serviceKey
matchKey
protocolServiceKey这些数据不仅用于展示,还会参与 consumer 侧的服务匹配、URL 恢复、方法级参数读取和多协议地址生成。
因此,Dubbo Java 的 metadata 更像:
应用运行时服务语义的完整模型。
5. 第一处核心差异:职责边界不同
Dubbo-Go 3.0 的 metadata 主要服务于应用级服务发现主链路。它关心的是:
consumer 如何从应用实例恢复出接口 URL?
consumer 如何知道某个接口由哪些应用提供?
provider 服务集合变化后,consumer 如何感知?Dubbo Java 的 metadata 职责明显更宽。它不仅关心调用链路,还关心:
服务定义如何上报?
metadata 如何存到元数据中心?
consumer 如何缓存 metadata?
mapping 如何动态监听?
metadata 获取失败如何重试?
dubbo-admin 如何查询服务元数据?
多协议 endpoint 如何表达?MetadataService 的接口设计也能体现这一点:它不仅用于 consumer 查询 provider 的 metadata,也可以服务于 console、OpenAPI 或治理侧查询。
可以简单总结为:
| 维度 | Dubbo-Go 3.0 | Dubbo Java 当前 |
|---|---|---|
| 核心定位 | 应用级服务发现的语义补全层 | 服务发现 + 元数据治理体系 |
| 主要目标 | 从应用实例恢复服务 URL | 恢复服务 URL,同时支持治理、查询、监听、缓存 |
| 复杂度 | 更轻量 | 更完整 |
| 成熟度 | 核心链路可用 | 生产治理能力更强 |
6. revision:metadata 的版本号
metadata 里最重要的概念之一就是 revision。
它可以理解成服务菜单的版本号。
如果 provider 当前暴露的服务集合是:
UserService
OrderService此时 revision 可能是:
rev-a如果后来 provider 又暴露了:
PaymentServicemetadata 内容变了,revision 也会变成:
rev-bconsumer 看到实例上的 revision 从 rev-a 变成 rev-b,就知道需要重新拉取 metadata。
在 Dubbo-Go 3.0 中,revision 的主要价值是避免 consumer 每次实例变化都重新拉取完整 metadata。
Dubbo Java 的 revision 绑定更深。在 MetadataInfo.calAndGetRevision() 中,Dubbo Java 会根据 app 和 services 计算 revision;当 revision 变化时,还会同步生成 rawMetadataInfo,用于上报远程 metadata center。
也就是说,在 Dubbo Java 中,revision 不只是一个判断标识,它还参与:
实例注册
实例更新
metadata center 存储
consumer 远程拉取
本地缓存
地址恢复这也是 Dubbo Java metadata 更工程化的地方。
7. mapping:从“接口名”找到“应用名”
应用级服务发现带来的最大变化是:
注册中心认识应用,但 consumer 习惯订阅接口。所以需要 service-app mapping。
例如:
org.example.UserService -> user-provider-app
org.example.OrderService -> order-provider-appprovider 导出服务时,会把“当前接口属于当前应用”这件事写入 mapping。consumer 订阅接口时,会先查 mapping,找到应用名,再去监听应用实例。
Dubbo-Go 3.0 已经具备这层能力,这也是它能够支撑应用级服务发现的关键。
Dubbo Java 做得更细。在 MetadataServiceNameMapping 中,provider 会把 serviceInterface 和 appName 注册到 metadata center。如果底层 metadata report 不支持直接注册 mapping,Dubbo Java 会走 CAS 流程:先读取旧内容,再把新应用名合并进去,然后带 ticket 更新。失败时还会随机等待并重试。
这解决的是并发注册问题。
假设两个应用同时声明自己提供同一个接口:
AppA -> UserService
AppB -> UserService如果没有 CAS,就可能出现互相覆盖。Dubbo Java 用 CAS + retry 保证最终 mapping 里能同时包含:
UserService -> AppA, AppB这就是老手需要关注的地方:metadata 不只是读写数据,还涉及分布式并发一致性。
8. 元数据中心:为什么不把所有数据都放注册中心?
很多人会问:既然 metadata 这么重要,为什么不直接把完整 metadata 放进注册中心?
原因很简单:太重。
接口级 URL 往往包含大量参数:
interface
group
version
methods
timeout
retries
serialization
protocol
port
application
timestamp
release
method-level configs
custom parameters如果一个应用有 50 个接口、100 个实例,注册中心推送完整 URL 时,数据量很容易膨胀成:
接口数 × 实例数 × URL 参数体积应用级服务发现把这个模型改成:
注册中心推轻量实例列表
metadata center 存完整服务语义
consumer 根据 revision 按需拉取这就是 metadata center 的价值。
Dubbo-Go 3.0 中,metadata center 主要用于:
存应用级 metadata
存 service-app mapping
支持 consumer 查询接口到应用的关系
支持 consumer 根据 revision 获取服务语义Dubbo Java 中,metadata center 的职责更丰富。MetadataReport 接口包含 provider metadata、service definition、app metadata、consumer metadata、exported URLs、subscribed data、service-app mapping 等多类能力。
这说明 Dubbo Java 的 metadata center 不只是 metadata 存储,而是服务定义、应用元数据、订阅数据、mapping 和监听能力的统一抽象。
9. 实例 metadata:轻量但关键
在应用级服务发现中,注册中心仍然需要存一些实例级 metadata。但这些 metadata 应该尽量轻。
Dubbo Java 的 ServiceInstanceMetadataUtils 中定义了一批关键字段,例如:
dubbo.metadata.revision
dubbo.metadata.storage-type
dubbo.endpoints
dubbo.metadata-service.url-params
dubbo.metadata-service.urls
dubbo.metadata.cluster
meta-v这些字段的作用是让 consumer 知道:
这个实例当前 metadata revision 是什么?
metadata 是存在远程中心,还是需要通过 provider MetadataService 获取?
这个实例有哪些协议 endpoint?
MetadataService 怎么访问?这些信息足够 consumer 找到完整 metadata,但又不会把完整服务语义塞进注册中心。
这体现了一个重要设计原则:
注册中心只放发现所需的最小信息,完整服务语义交给 metadata。
10. Consumer 如何恢复最终服务地址?
这是 metadata 在运行时最核心的作用。
以 Dubbo Java 为例,consumer 收到应用实例变化后,ServiceInstancesChangedListener 大致会做几件事。
第一步,按 revision 给实例分组:
revision-1 -> instance1, instance2, instance3
revision-2 -> instance4, instance5第二步,每个 revision 只获取一次 MetadataInfo。
如果实例里已经带了可用 MetadataInfo,就直接使用;否则调用类似下面的远程获取逻辑:
serviceDiscovery.getRemoteMetadata(revision, instances)第三步,解析 MetadataInfo 里的 ServiceInfo。
第四步,根据 protocol、port、endpoint,把应用实例重新转换成 Dubbo URL。
第五步,通知 consumer 的 NotifyListener,最终刷新 Registry Directory。
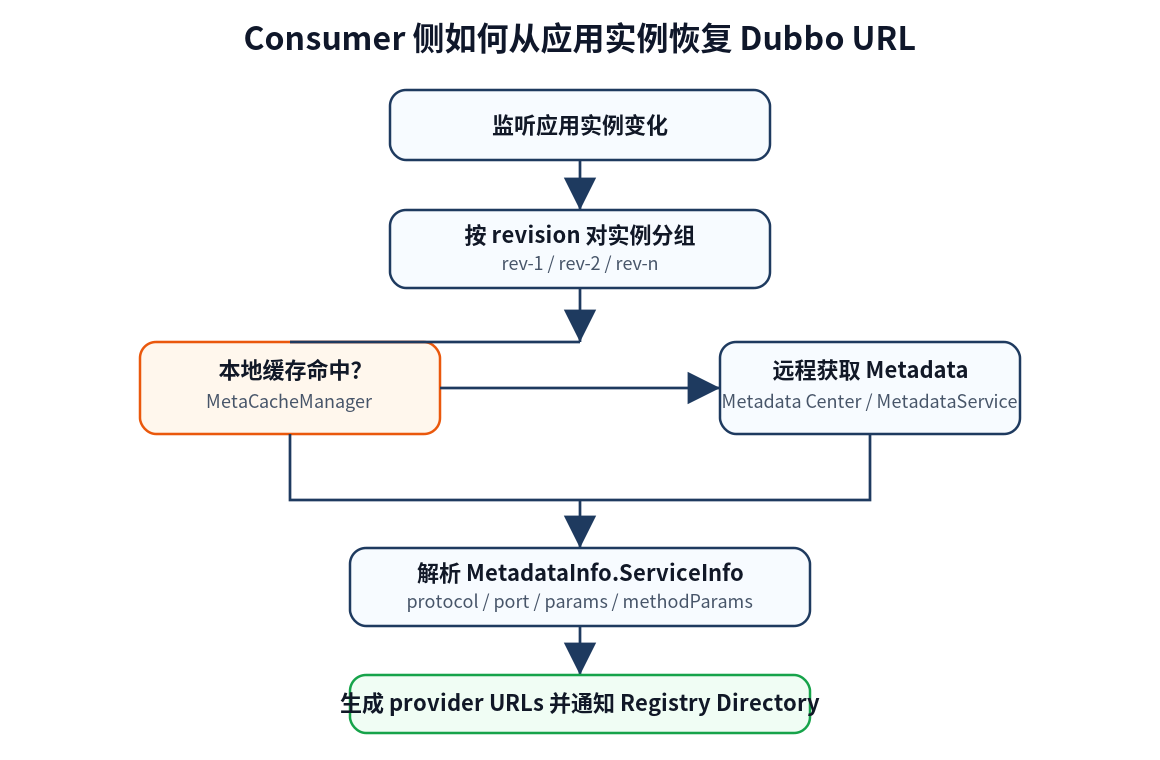
这也是 metadata 降低地址推送成本的关键。如果 100 个实例的 revision 都一样,consumer 理论上只需要获取一份 metadata,而不是解析 100 份完整服务 URL。
11. Dubbo Java 如何获取远程 metadata?
Dubbo Java 大致有两条路径。
第一种,从 metadata center 拉取。
如果实例 metadata 标记 storage type 是 remote,那么 consumer 会通过 metadata report 获取 app metadata。
第二种,通过 provider 暴露的 MetadataService 拉取。
如果不是 remote storage,consumer 会临时 refer provider 的 MetadataService,然后调用:
getMetadataInfo(revision)MetadataUtils.getRemoteMetadata() 会根据 metadata storage type 选择不同路径。
这带来的好处是灵活:如果有稳定的 metadata center,可以集中存储;如果没有,也可以通过 provider 自身暴露的 MetadataService 获取。
Dubbo-Go 3.0 也有 MetadataService 的概念,但能力边界更偏主链路需要;Dubbo Java 的 MetadataService 则已经成为 consumer、console、OpenAPI、实例 metadata 监听等能力的统一入口之一。
12. 可用性:metadata 挂了会发生什么?
metadata 不是锦上添花。
在应用级服务发现中,如果 consumer 拿到了实例,但拿不到 metadata,就会出现一个尴尬状态:
我知道 provider 活着,但我不知道它提供什么接口。所以 metadata 的可用性要求很高。
Dubbo Java 在这方面做了不少保护。在 AbstractServiceDiscovery.getRemoteMetadata() 中,consumer 会先查本地缓存。如果缓存命中,就直接使用;如果没命中,再远程拉取。远程拉取失败时会重试,成功后写入缓存。
在 ServiceInstancesChangedListener 中,如果某些 revision 的 metadata 获取失败,会统计 empty metadata。如果所有 revision 都失败,本次地址通知不会生效,而是提交后续 retry 任务。
这说明 Dubbo Java 对 metadata 的可用性做了多层兜底:
本地缓存
远程拉取重试
empty metadata 保护
地址刷新 retry
部分成功时继续通知Dubbo-Go 3.0 的 metadata 主链路已经具备,但相比 Java,缓存、失败保护、动态监听和治理侧配套还没有那么成熟。
13. 性能价值:metadata 如何降低地址推送时延?
metadata 的性能价值不是“计算一个 revision 很快”这么简单。真正的价值在于改变了数据流。
传统接口级注册模型是:
注册中心推送完整接口 URL 列表应用级服务发现 + metadata 之后变成:
注册中心推送轻量应用实例
consumer 按 revision 拉取 metadata
consumer 本地组合最终 URL这样可以带来几个明显收益。
第一,注册中心推送包更小。 它不需要每次推完整接口 URL 和大量参数,只需要推实例地址、revision、endpoint、metadata storage type 等少量信息。
第二,相同 revision 的实例共享 metadata。 100 个实例如果服务集合一样,就可以共享一份 MetadataInfo。
第三,实例变化和服务语义变化解耦。 扩容、缩容、重启通常只改变实例列表,不改变服务接口。consumer 不需要每次都重新解析服务语义。
第四,本地缓存减少远程访问。 Dubbo Java 会通过 MetaCacheManager 和 revision 缓存复用 metadata。
所以 metadata 降低地址推送时延的本质是:
少推数据、少拉数据、少解析数据、少重复通知。
14. Dubbo-Go 与 Dubbo Java 的整体差异
可以把两者放在同一个演进坐标上看。
Dubbo-Go 3.0 已经实现了应用级服务发现所必需的核心能力:
应用服务集合
revision
service-app mapping
MetadataService
metadata report
consumer 侧服务视图恢复它解决的是“应用级服务发现能不能跑通”的问题。
Dubbo Java 当前实现则更进一步,把 metadata 做成了完整体系:
服务定义上报
应用级 metadata 发布
mapping CAS 注册
mapping 动态监听
实例 metadata 表达
多协议 endpoints
MetadataService 远程查询
metadata 本地缓存
失败重试
empty metadata 保护
治理侧查询入口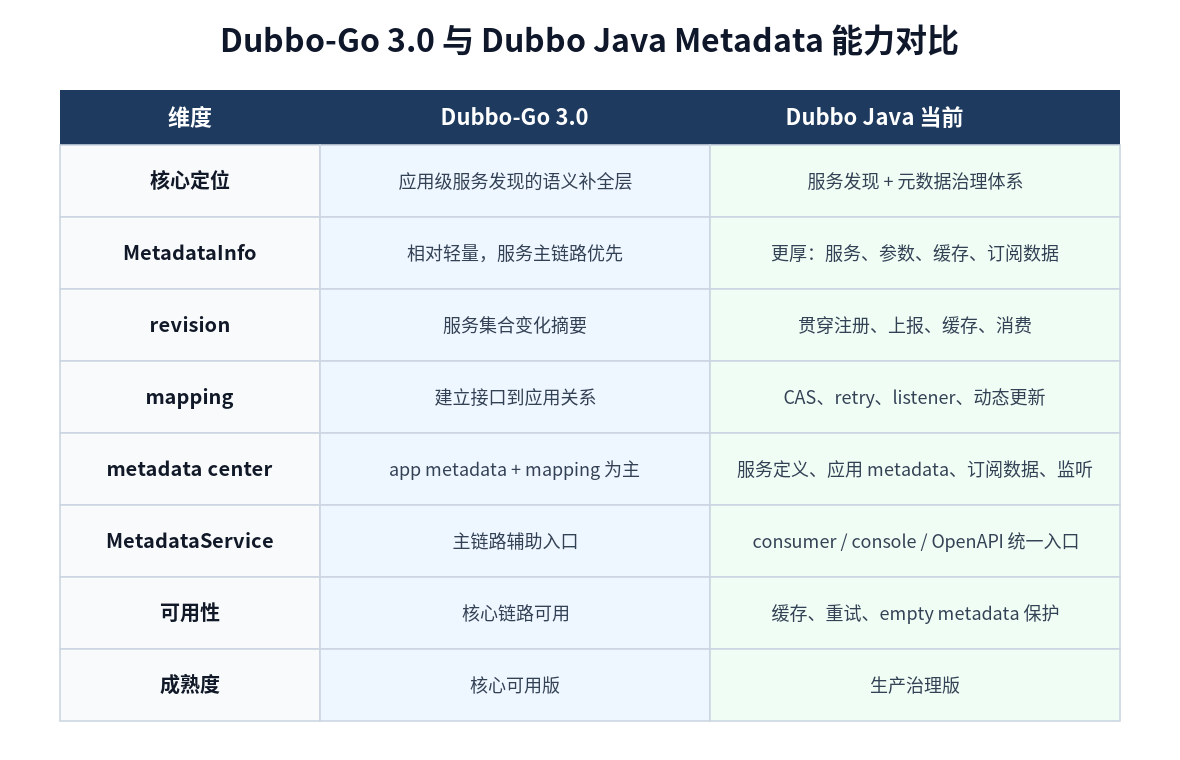
| 对比项 | Dubbo-Go 3.0 | Dubbo Java 当前 |
|---|---|---|
| 设计目标 | 应用级服务发现落地 | 应用级服务发现 + 元数据治理 |
| MetadataInfo | 相对轻量 | 更厚,包含运行期缓存和多类参数 |
| revision | 服务集合变化摘要 | 应用 metadata 版本号,贯穿注册、上报、缓存、消费 |
| mapping | 能建立接口到应用关系 | 支持 CAS、retry、listener、动态更新 |
| metadata center | app metadata + mapping 为主 | 服务定义、应用 metadata、mapping、订阅数据、监听 |
| MetadataService | 主链路辅助 | consumer / console / OpenAPI / introspection 入口 |
| 可用性 | 核心链路可用 | 缓存、重试、empty protection 更完整 |
| 性能优化 | revision + 按需拉取 | revision 分组、缓存、参数过滤、method cache、多协议 endpoint |
| 成熟度 | 核心可用版 | 生产治理版 |
所以两者不是方向不同,而是阶段不同。
15. 结论
总结两者差异:
Dubbo-Go 3.0 metadata 更像“应用级发现的语义层”;
Dubbo Java metadata 更像“围绕应用级发现构建出来的元数据治理体系”。这就是 Dubbo 3 metadata 设计的核心:
把高频变化的地址和低频变化的服务语义拆开,再通过 revision、mapping、metadata center、MetadataService 和本地缓存,把地址推送、服务恢复和治理查询连接成一条完整链路。
